Java基础

接⼝和抽象类有什么共同点和区别?
共同点 :
-
都不能被实例化。
-
都可以包含抽象⽅法。
-
都可以有默认实现的⽅法(Java 8 可以⽤ default 关键字在接⼝中定义默认⽅法)。
区别 :
-
接⼝主要⽤于对类的⾏为进⾏约束,你实现了某个接⼝就具有了对应的⾏为。抽象类主要⽤于代码复⽤,强调的是所属关系。
-
⼀个类只能继承⼀个类,但是可以实现多个接⼝。
-
接⼝中的成员变量只能是 public static final 类型的,不能被修改且必须有初始值,⽽抽象类的成员变量默认 default,可在⼦类中被重新定义,也可被重新赋值。
⾯向对象三⼤特征
-
封装 Java中提供了关键字private、protected和public来控制成员的访问权限。
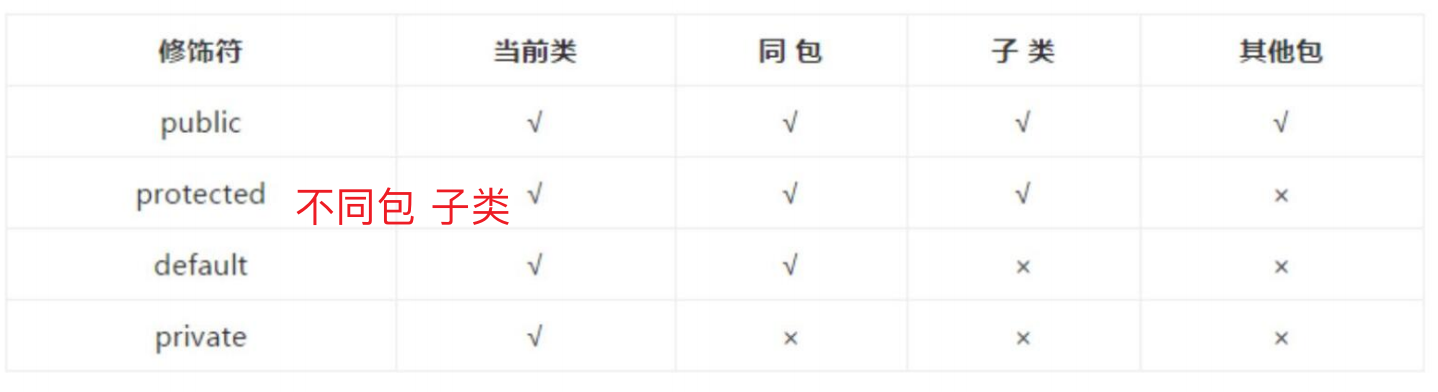
-
继承 单继承,多实现,怕重名 命名冲突
-
多态 多态存在的3个条件:1)继承;2)重写;3)⽗类引⽤指向⼦类对象
引⽤类型变量发出的⽅法调⽤的到底是哪个类中的⽅法,必须在程序运⾏期间才能确定
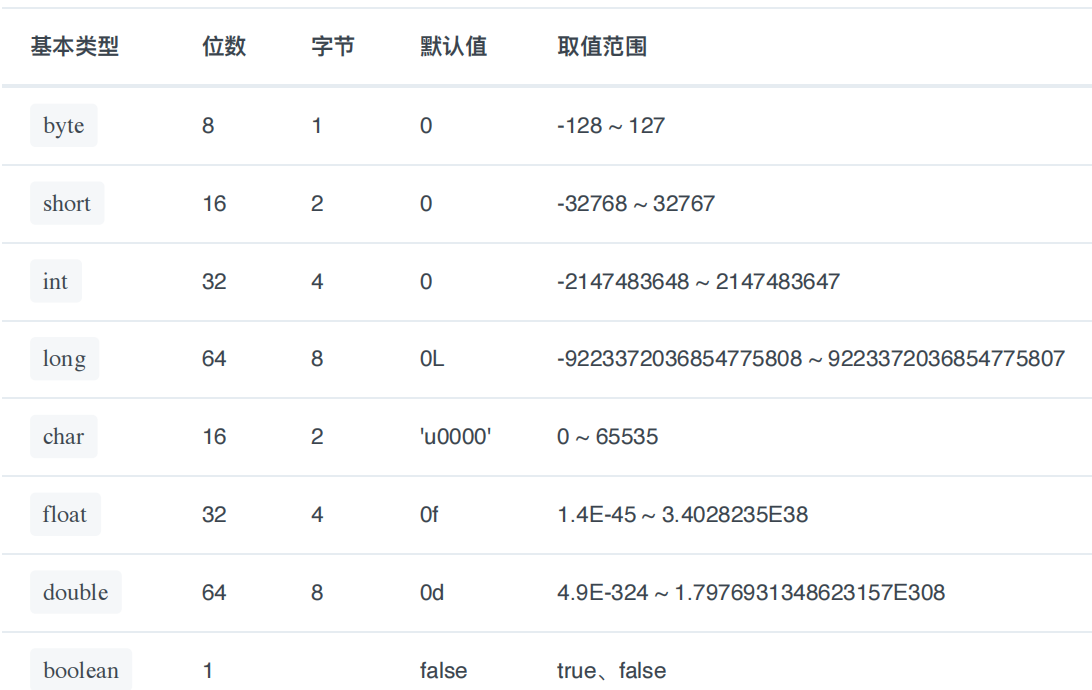
Java 中的⼏种基本数据类型了解么?
-
整形 byte short int long 1 2 4 8
-
字符型 char 2
-
浮点型 floot doblue 4 8
-
布尔型 boolean 1
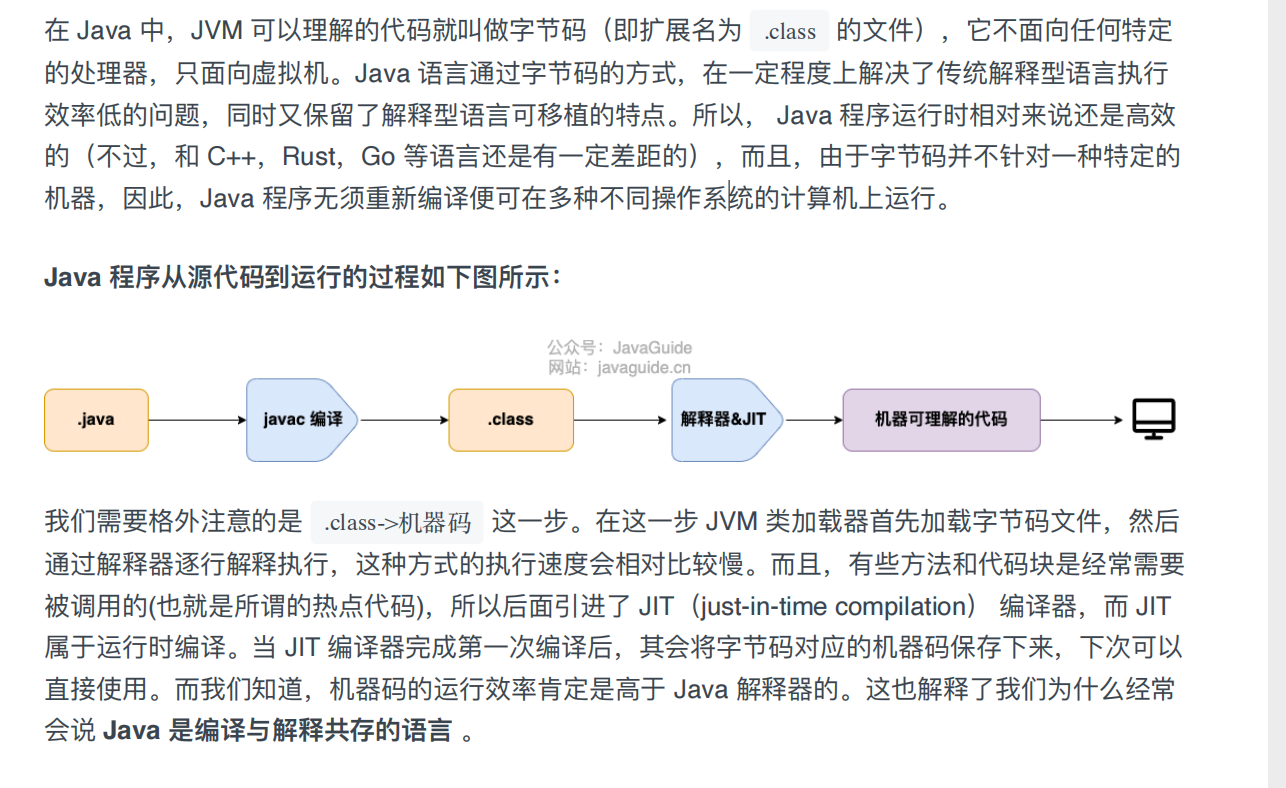
什么是字节码?采用字节码的好处是什么?
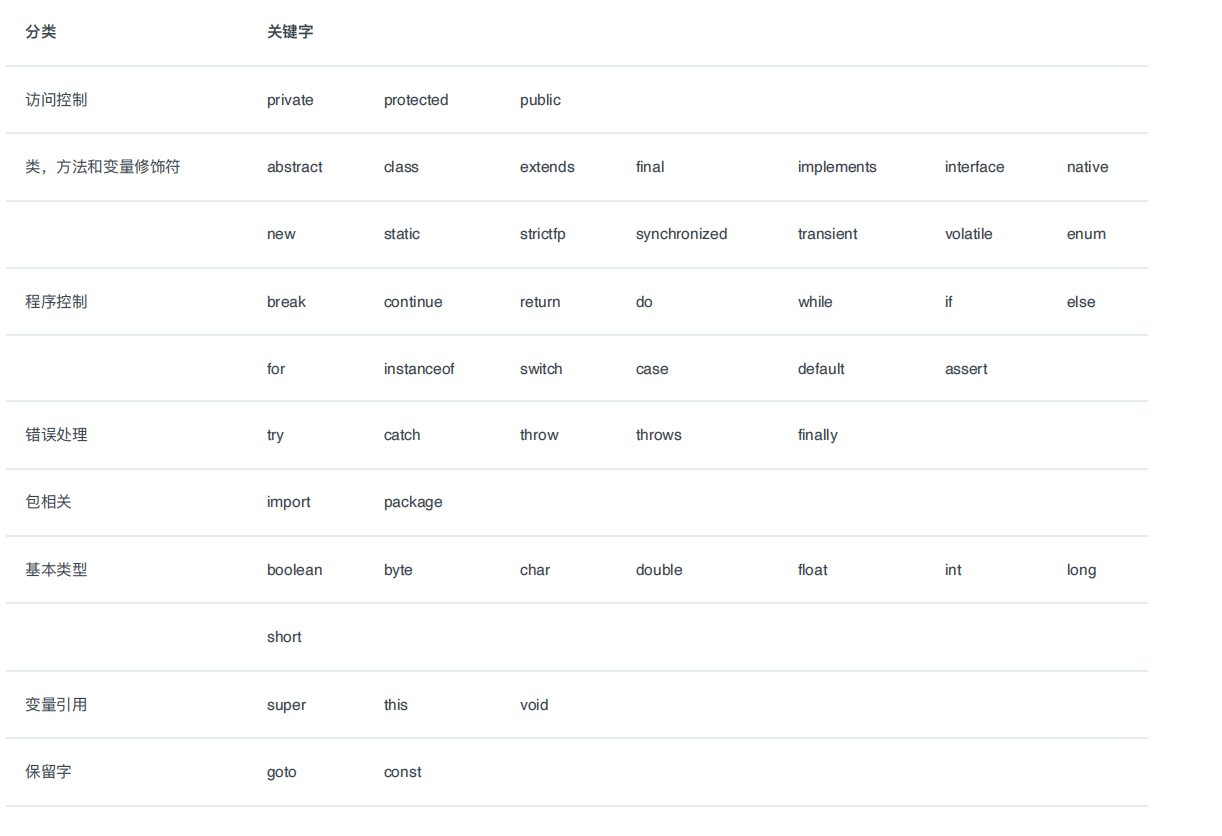
Java 语⾔关键字有哪些?
成员变量与局部变量的区别?
-
语法形式 :从语法形式上看,成员变量是属于类的,⽽局部变量是在代码块或⽅法中定义的变量或是⽅法的参数;成员变量可以被 public , private , static 等修饰符所修饰,⽽局部变量不能被访问控制修饰符及 static 所修饰;但是,成员变量和局部变量都能被 final 所修饰。
-
存储⽅式 :静态变量存储在类的静态区,不属于任何一个对象,而普通成员变量则属于每一个对象。普通成员变量存在于堆内存中,局部变量则存在于栈内存。
-
⽣存时间 :从变量在内存中的⽣存时间上看,成员变量是对象的⼀部分,它随着对象的创建⽽存在,⽽局部变量随着⽅法的调⽤⽽⾃动⽣成,随着⽅法的调⽤结束⽽消亡。
静态变量的生命周期从程序开始运行到程序结束,不会因为对象的创建和销毁而改变
-
默认值 :从变量是否有默认值来看,成员变量如果没有被赋初始值,则会⾃动以类型的默认值⽽赋值(⼀种情况例外:被 final 修饰的成员变量也必须显式地赋值),⽽局部变量则不会⾃动赋值。
方法的重载和重写
方法的重载和重写都是实现务态的方式,区别在于前者实现的是编译时的多态性,而后者实现的是运行时的多态性。
重载:发生在同一个类中,方法名相同参数列表不同(参数类型不同、个数不同、顺序不同),与方法返回值和访问修饰符无关,即重载
的方法不能根据返回类型进行区分重写:发生在父子类中,方法名、参数列表必须相同,返回值小于等于父类,抛出的异常小于等于父
类,访问修饰符大于等于父类(里氏代换原则);如果父类方法访问修饰符为private则子类中就不是重写。
包装类
-
缓存
-
null
-
范形
-
基本数据类型的局部变量存放在 Java 虚拟机栈中的局部变量表中,基本数据类型的成员变量
(未被 static 修饰 )存放在 Java 虚拟机的堆中。包装类型属于对象类型,我们知道⼏乎所有
对象实例都存在于堆中。
-
装箱:将基本类型⽤它们对应的引⽤类型包装起来;
拆箱:将包装类型转换为基本数据类型;
装箱其实就是调⽤了 包装类的 valueOf() ⽅法,拆箱其实就是调⽤了xxxValue()
Comparable和Comparator的区别?
Comparable接口实际上是出自java.lang包,它有一个compareTo(Objectobj)方法用来排序
Comparator接口实际上是出自java.util包,它有个compare(Object obj1,Object obj2)方法用来排序
一般我们需要对一个集合使用自定义排序时,我们就要重写compareTo方法或compare方法,当我们需要对某一个集合实现两种排序方式,比如一个song对象中的歌名和歌手名分别采用一种排序方法的话,我们可以重写compareTo方法和使用自制的Comparator方法或者以两个Comparator来实现歌名排序和歌星名排序,第二种代表我们只能使用两个参数版的Collections.sort()
String str=“i“与 String str=new String(“i“)一样吗? 0 1
一、直接赋值:String str=“abc”;
1、JVM首先会去字符串常量池中查找是否存在"abc"这个对象
2、如果不存在,则在字符串池中创建"abc"这个对象,然后将池中"这个对象的引用地址返回给字符串常量str,这样str会指向池中这个字符串对象;
3、如果存在,则不创建任何对象,直接将池中这个对象的引用地址返回,赋给字符串常量str。
二、使用new关键字创建:String str= new String(“abc”);
运行阶段,无论常量池中或者堆中是否存在该字符串,都会在堆中创建一个字符串对象,然后将堆中的这个对象的地址返回赋给引用str,这样,str就指向了堆中创建的这个"abc"字符串对象;
三、结论
String str=“abc” 可能创建一个对象或者不创建对象,如果这个字符串在常量池里不存在,会在常量池创建;如果这个对象已经存在,str直接指向这个常量池里的对象。
String str = new String(“abc”) 至少创建一个对象,也可能两个。因为用到new 关键字,一定会在堆中创建一个对象,同时,如果这个字符串在常量池里不存在,也会在常量池创建这个对象。
描述一下jvm内存模型,以及这些空间的存放的内容?
findClass 类加载逻辑
loadClass 如果父类加载器加载失败则会调用自定义的findClass方法
defineClass 把类字节数组变成类
如果不打破双亲委派机制,重写findClass方法即可
如果打破双亲委派机制,重写整个loadClass方法
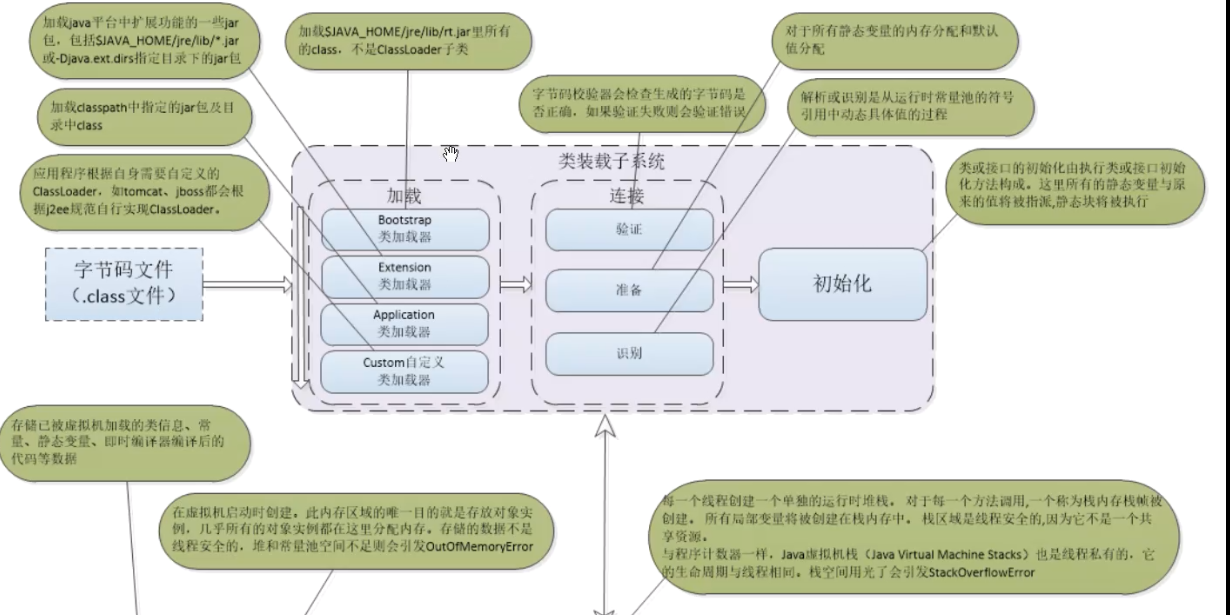
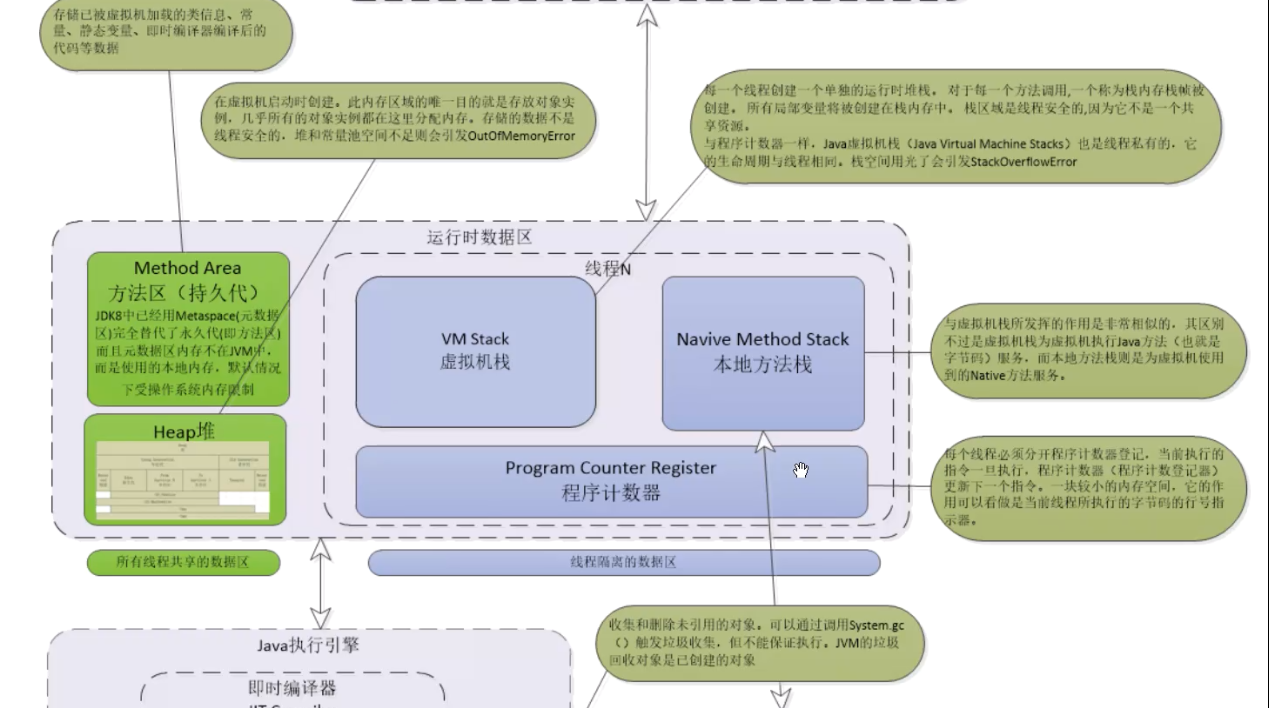
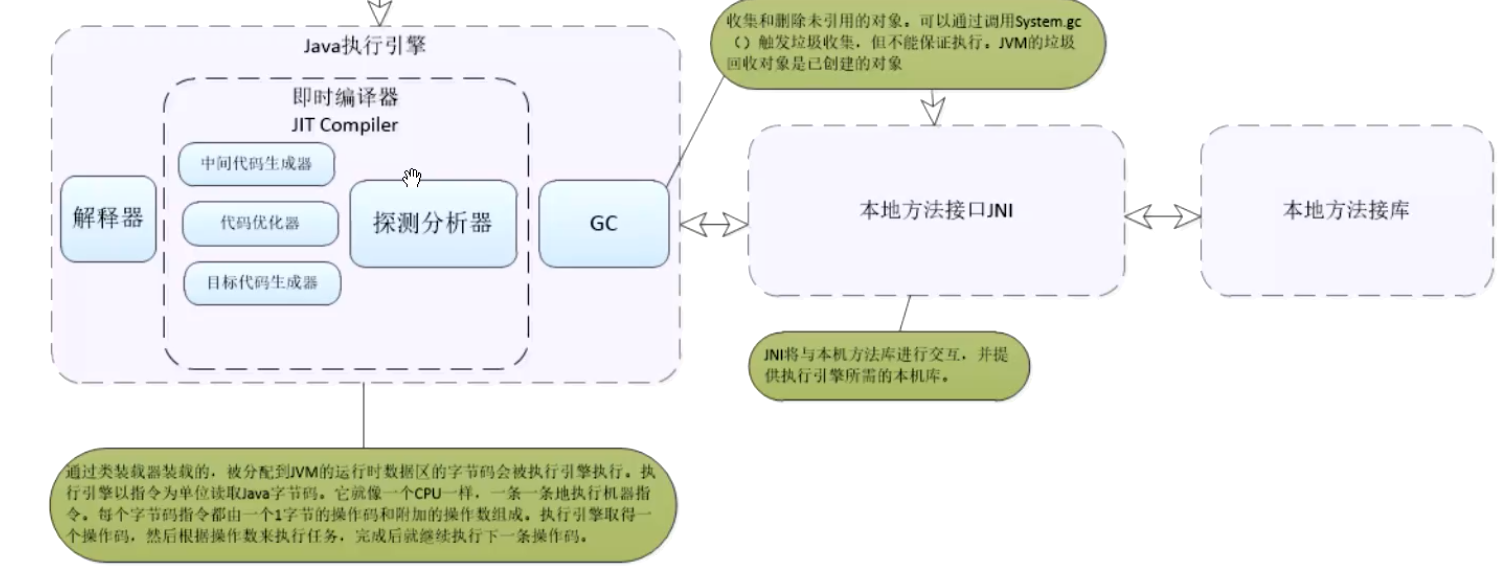
2.堆内存划分的空间,如何回收这些内存对象,有哪些回收算法?
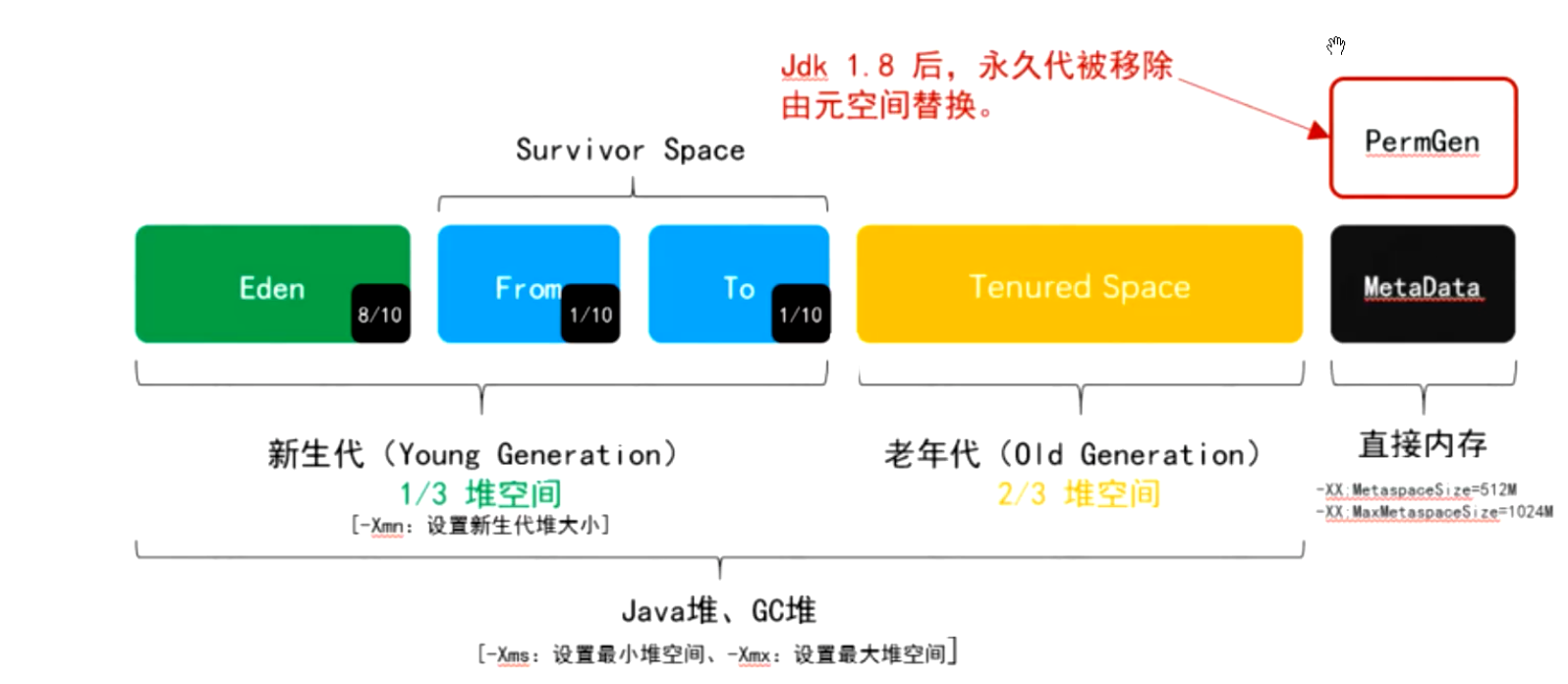
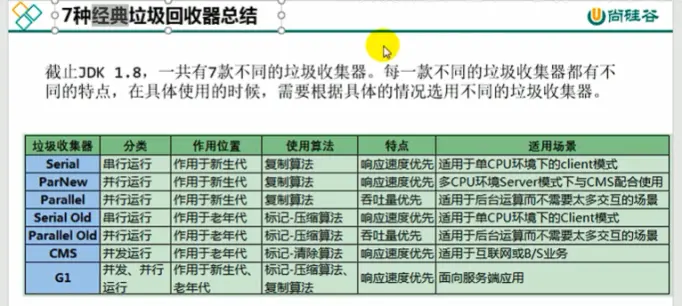
垃圾回收算法是管理内存的重要手段。根据内存的分布情况和特点,常用的垃圾回收算法主要包括以下三种:
- 标记清除(Mark-Sweep):首先标记所有存活的对象,然后清除所有未被标记的对象。该算法的缺点是会产生内存碎片,不利于程序后续的内存分配。
- 复制(Copying):将内存分为两个部分,每次只使用其中的一部分。当一部分的内存使用完毕后,将其中的存活对象复制到另一个部分中,然后回收前一部分的所有内存。该算法实现简单,适用于新生代的垃圾回收。
- 标记整理(Mark-Compact):首先标记所有存活的对象,然后将所有存活的对象移动到一端,然后清除其余的内存。该算法相对于标记清除算法来说,可以避免内存碎片的产生,但是需要耗费额外的时间来移动存活对象。
需要注意的是,不同的垃圾回收器可能会采用不同的算法来管理内存。例如,CMS垃圾回收器采用的是标记清除算法,而G1垃圾回收器则采用了标记整理和复制两种算法的组合
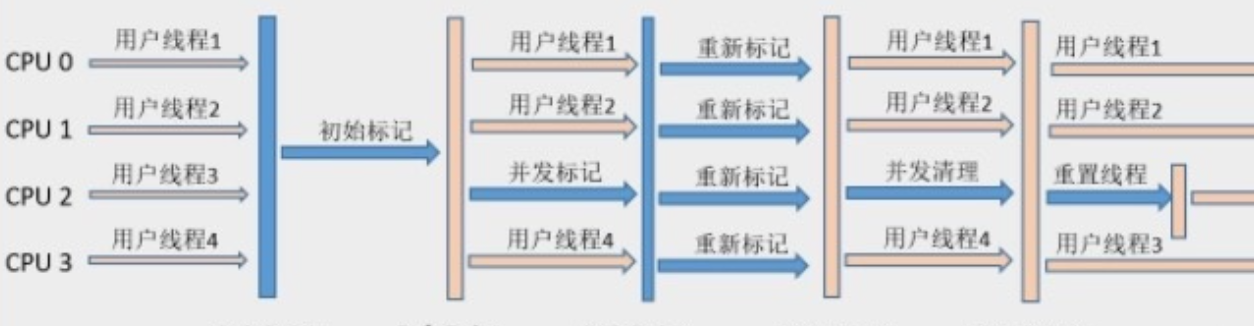
- 初始标记:首先标记出所有的GC Roots直接关联的存活对象,然后标记所有被直接关联的对象,这个过程需要暂停应用线程。
- 并发标记:在初始标记完成的基础上,进行并发标记,找出所有存活的对象。
- 最终标记:最后的标记阶段,将前两个阶段中并发标记产生的待清理的存活对象重新标记,以防止并发标记过程中出现漏标情况。
- 混合回收:根据各个小块的存活对象来估算该块内存的清理价值,选择价值最高的块进行混合回收,将其余块中的存活对象复制到其他块中,并清理掉当前块。此过程可以同时清理新生代和老年代,并可以在多个垃圾回收器线程同时进行。


Java 中的接口和抽象
首先,抽象类是一个类,而接口是一个纯粹的接口。它们之间的主要区别在于:
- 抽象类可以包含实例变量和实例方法。但是,接口只包含常量和抽象方法。
- 在 Java 中,每个类只能继承自一个父类,但可以实现多个接口。因此,使用接口可以使类更灵活,使得类可以同时具备不同的行为。
- 另外,抽象类中的方法可以有实现,而接口中所有的方法都必须是抽象的,即不包含具体的实现。
Java 中的泛型。
泛型是 Java 5 引入的一个重要特性。它允许程序员在设计类、接口和方法时使用类型参数,从而使得类、接口和方法更加灵活和通用化。
具体来说,泛型的作用和优势包括:
- 提高代码的安全性和可读性。通过指定类型参数,可以在编译期就发现类型不匹配的错误,从而减少运行时出错的概率。同时,使用泛型可以使代码更加易读,因为我们可以使用更直观的类型名称来理解代码的含义。
- 增加代码的复用性。通过定义泛型类或泛型方法,可以实现对不同数据类型的支持,从而减少代码的重复度。
- 提高代码的性能。泛型类和方法在运行时会根据类型参数进行特化,从而减少了自动装箱和拆箱操作等额外开销,提高了代码的执行效率。
在使用方面,泛型主要有以下几种使用场景:
- 定义泛型类:通过
class关键字后面加上类型参数,可以定义一个泛型类。例如:public class MyClass<T> { ... }。 - 定义泛型接口:通过
interface关键字后面加上类型参数,可以定义一个泛型接口。例如:public interface MyInterface<T> { ... }。 - 定义泛型方法:通过在方法声明时指定类型参数,可以定义一个泛型方法。例如:
public <T> void myMethod(T param) { ... }。 包括返回值
反射的基本步骤
反射(Reflection)是 Java 提供的一种机制,它允许程序在运行时动态地获取类的信息、调用对象的方法和属性,以及创建类的实例等。
@Test
public void classTest() throws Exception {
// 获取Class对象的三种方式
logger.info("根据类名: \t" + User.class);
logger.info("根据对象: \t" + new User().getClass());
logger.info("根据全限定类名:\t" + Class.forName("com.test.User"));
// 常用的方法
logger.info("获取全限定类名:\t" + userClass.getName());
logger.info("获取类名:\t" + userClass.getSimpleName());
logger.info("实例化:\t" + userClass.newInstance());
}- 获取 Class 对象 使用 Class 类的 forName() 静态方法可以获取指定类名对应的 Class 对象,例如:
Class<?> classObj = Class.forName("com.example.MyClass");- 创建对象 通过 Class 对象的 newInstance() 方法可以创建类的实例,例如:
MyClass obj = (MyClass) classObj.newInstance();- 获取构造方法 通过 Class 类的 getConstructor() 或 getDeclaredConstructor() 方法可以获取相应构造方法的 Constructor 对象,例如:
Constructor<?> constructor = classObj.getConstructor(int.class, String.class);- 调用构造方法 使用 Constructor 类的 newInstance() 方法可以调用相应的构造方法来创建类的实例,例如:
MyClass obj = (MyClass) constructor.newInstance(123, "hello");- 获取方法 使用 Class 类的 getMethod() 或 getDeclaredMethod() 方法可以获取相应方法的 Method 对象,例如:
代码Method method = classObj.getMethod("myMethod", int.class, String.class);- 调用方法 使用 Method 类的 invoke() 方法可以调用相应的方法,例如:
method.invoke(obj, 456, "world");- 获取字段 通过 Class 类的 getField() 或 getDeclaredField() 方法可以获取相应字段的 Field 对象,例如:
Field field = classObj.getDeclaredField("myField");- 访问/修改字段 通过 Field 类的 get() 和 set() 方法可以访问/修改相应的字段,例如:
Object value = field.get(obj);
field.set(obj, newValue);序列化
-
序列化:将对象写入到IO流中
-
反序列化:从IO流中恢复对象
序列化:把对象转换为字节序列的过程称为对象的序列化。
反序列化:把字节序列恢复为对象的过程称为对象的反序列化。 -
意义:序列化机制允许将实现序列化的Java对象转换位字节序列,这些字节序列可以保存在磁盘上,或通过网络传输,以达到以后恢复成原来的对象。序列化机制使得对象可以脱离程序的运行而独立存在。
-
使用场景:所有可在网络上传输的对象都必须是可序列化的,比如RMI(remote method invoke,即远程方法调用),传入的参数或返回的对象都是可序列化的,否则会出错;所有需要保存到磁盘的java对象都必须是可序列化的。通常建议:程序创建的每个JavaBean类都实现Serializeable接口。
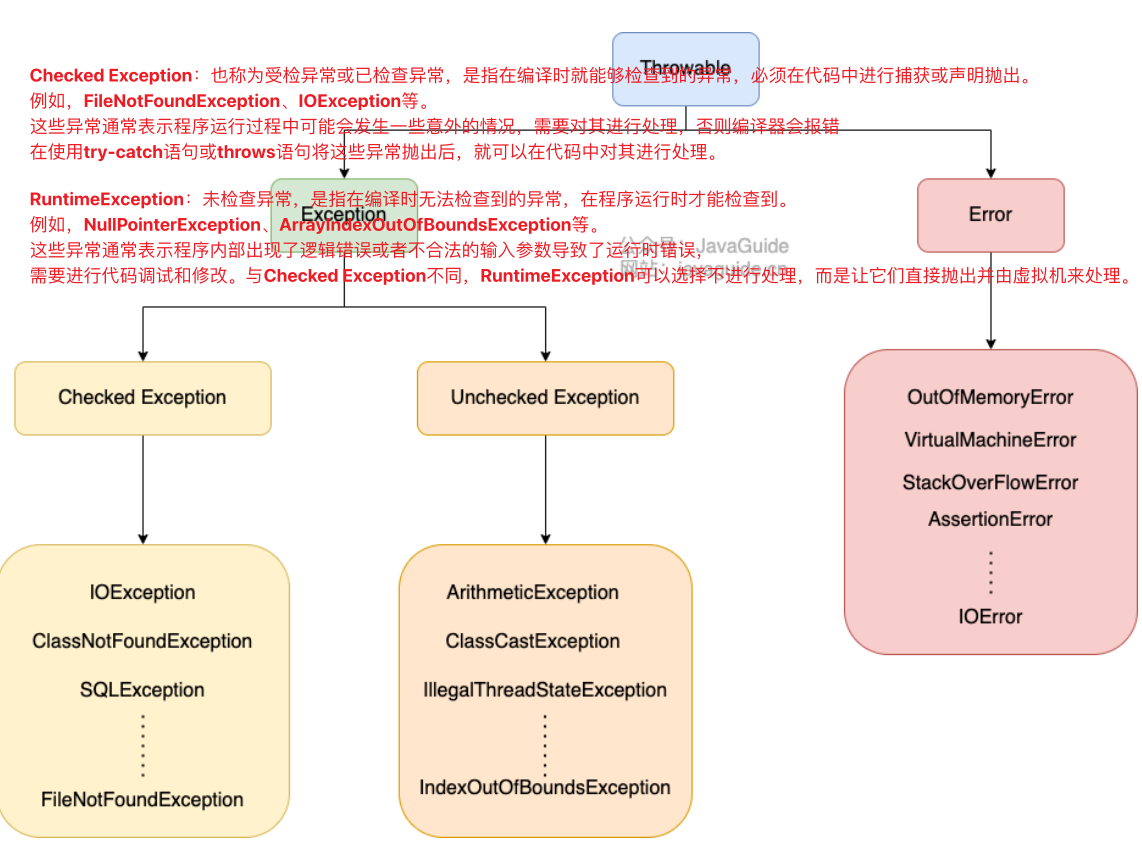
Java异常关键字
-
·try-用于监听。将要被监听的代码(何能抛出异常的代码)放在ty语句块之内,当try语句块内发生异常时,异常就被抛出。
-
·catch-用于捕获异常。catch用来捕获try语句块中发生的异常。
-
·finally-finally语句块总是会被执行。它主要用于回收在try块里打开的物资源(如数据库连接、网络连接和磁盘文件)。只有finally块,执行完成之后,才会回来执行try或者catch:块中的return或者throwi语句,如果finally中使用了returni或者throw等终止方法的语句,则就不会跳回执行,直接停止。
-
·throw-用于抛出异常。
-
·throws-用在方法签名中,用于声明该方法可能地出的异常。
Throwable 类常⽤⽅法有哪些?
String getMessage() : 返回异常发⽣时的简要描述
String toString() : 返回异常发⽣时的详细信息
String getLocalizedMessage() : 返回异常对象的本地化信息。使⽤ Throwable 的⼦类覆盖这个⽅法,可以⽣成本地化信息。如果⼦类没有覆盖该⽅法,则该⽅法返回的信息与 getMessage() 返回的结果相同
void printStackTrace() : 在控制台上打印 Throwable 对象封装的异常信息
Arrays.sort()用的什么排序算法
暂时网上看过很多JDK8中Arrays.sort的底层原理,有些说是插入排序,有些说是归并排序,也有说大于域值用计数排序法,否则就使用插入排序。。。其实不全对。让我们分析个究竟:
先说总结:
数组长度为n,则1 <= n < 47 使用插入排序
数组长度为n,则47 <= n < 286 使用使用快速排序
数组长度为n,则286 < n 使用归并排序或快速排序(有一定顺序使用归并排序,毫无顺序使用快排)
Comments NOTHING