数据挖掘笔记

声明
整合自多位大佬,或者互联网,个人整理所得,非原创
名词解释
-
分值:20分
-
要求
- 题目给出中文名称要写出英文全称
- 题目给出英文名称要写出中文全称
- 给出解释
1 数据挖掘/数据分析技术 Data Mining
是从大量的、不完全的、有噪声的、模糊的、随机的数据集中识别有效的、新颖的、潜在有用的,以及最终可理解的模式的非平凡过程。它是一门涉及面很广的交叉学科,包括机器学习、数理统计、神级网络、数据库、模式识别、粗糙集等相关技术。
2 机器学习 Machine Learning
研究如何使用机器来模拟人类学习活动的一门学科。
3 信息熵 Entropy
在信息论中,熵是一种信息度量单位。在决策树构造算法中根据熵值来计算信息增益。
4 权威页面
是指包含需求信息的最佳资源页面。是指与某个领域或者某个话题相关的高质量网页
5 传统数据仓库技术
使用ETL(Extract,Transform,Load)或ETCL(Extract,Transform,Clean,Load)工具实现数据的导出、转换、清洗和装入工具。使用操作型数据存储(Operational Data Store,ODS)存储明细数据,使用数据集市和数据仓库计数实现面向主题的历史数据存储,使用多维分析工具进行前端展现,以及使用数据仓库工具提供的挖掘引擎或基于单独的数据挖掘工具进行预测分析等。
6 广义知识 Generalization
是指描述类别特征的概括性知识。这类数据挖掘系统是对细节数据所蕴含的概念特征信息的概括和抽象的过程。
7 关联知识 Association
反映一个事件和其他事件之间的依赖或关联。关联知识挖掘的目的就是找出数据库中隐藏的关联信息。
8 AGNES AGglomerative Nesting 凝聚的层次聚类
自底向上凝聚的算法,先将每个对象作为一个簇,然后这些簇根据某些准则(类间距离最近的两个点)被一步步地合并,直到某个终结条件被满足(达到定义的簇的数目)。(写这些就够了)
两个簇间的相似度由这两个不同簇中距离最近的数据点对的相似度来确定。
9 DIANA Divisive ANAlysis 分裂的层次聚类
自顶向下分裂的算法,它首先将所有对象置于一个簇中,然后逐渐细分为越来越小的簇,直到达到了某个终结条件(达到了某个希望的簇数目,或两个最近簇之间的距离超过了某个阈值)。
10 时间序列 Time Series
统计意义上来讲,时间序列是将某一指标在不同时间上的不同数值,按照时间先后顺序排列而成的数列。
11 大数据 bigdata
指一种规模大到在获取、存储、管理、分析 方面大大超出了传统数据库软件工具能力范围的数据 集合,具有海量的数据规模、快速的数据流转、多样 的数据类型和价值密度低四大特征。
12 噪声环境下的密度聚类算法算法
(Density-Based Spatial Clustering of Applications with Noise, DBSCAN算法)

简答题
- 分值:2*10分
- 题目(什么是)
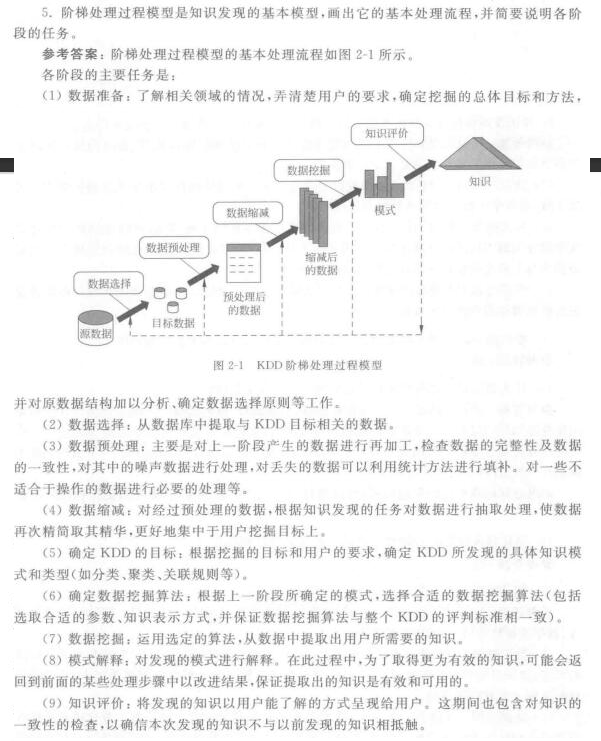
1 知识发现(Knowledge Discovery in Database,KDD)
是一个系统化的工作,必须对可以利用的源数据进行分析,确定合适的挖掘目标,然后才能着手系统的设计和开发。
-
KDD是一个多步骤的处理过程,一般分为
问题定义
数据采集(数据库采集,系统日志采集,网络数据采集,感知设备数据采集)
数据预处理( 清洗 、转换 -->三种规格化、描述、选择、抽取)
数据挖掘 (十大经典算法、PCA、NN、DL…)
模式评估
-
知识发现的过程
数据源中抽取感兴趣的数据,并把它组织成适合挖掘的数据组织形式;
调用相应的算法生成所需的知识;
对生成的知识模式进行评估,并把有价值的知识集成到企业的智能系统中。 -
2 爬虫
spider,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本
3 聚类分析
-
定义
把一组个体按照相似性归为若干类别。
聚类属于无监督学习(Unsupervised Learning)。是指根据给定一组对象的描述信息,发现由具有共同特性的对象构成簇
的过程。
-
目的
使同一类别的个体之间的差别尽可能地小,不同类别上的个体间的差别尽可能地大
-
基本概念
在没有训练的条件下,把样本划分为若干类
无类别标签的样本
无监督学习
-
评价准则
类间距离大
类内距离小
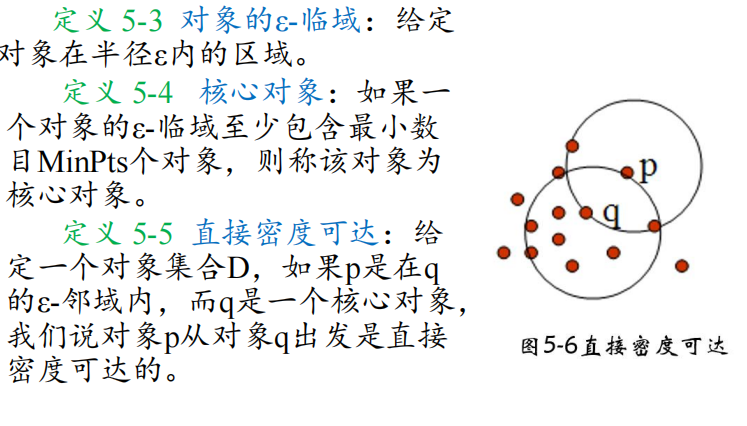
4 DBSCAN算法 考描述
-
密度聚类方法
指导思想是,只要一个区域中,点的密度大于某个阈值,就把它加到与之相连的簇中去。
核心思想:将密度相连的核心对象点都放在一个簇中。
-
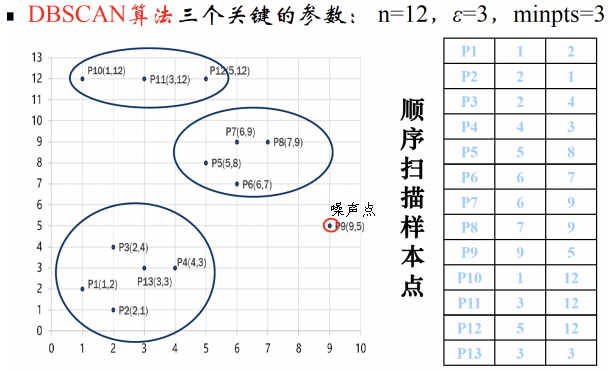
DBSCAN:Density-Based Spatial Clustering of Applications with Noise,噪声环境下的密度聚类算法
三个关键的参数: n=12,ε=3,minpts=3
-
DBSCAN算法:如果一个点q的区域内包含多于MinPts个对象,则创建一个q作为核心对象的簇。然后,反复地寻找从这些核心对象直接密度可达的对象,把一些密度可达簇进行合并。当没有新的点可以被添加到任何簇时,该过程结束。


-
优点
- 聚类速度快且能够有效处理噪声点和发现任意形状的空间聚类;
- 与K-MEANS比较起来,不需要输入要划分的聚类个数;
- 聚类簇的形状没有偏倚;
- 对噪声数据不敏感。
缺点
- 当数据量增大时,要求较大的内存支持I/O消耗也很大;
- 当空间聚类的密度不均匀、聚类间距差相差很大时,聚类质量较差,因为这种情 况下参数MinPts和 $\epsilon$ 选取困难(对半径和Minpoints敏感)。
- 算法聚类效果依赖与距离公式选取, 实际应用中常用欧式距离,对于高维数据,存在“维数灾难”。
5 K 中心点算法定义

6 时间序列挖掘
-
名词解释
时间序列(Time Series),从统计意义上来讲,时间序列是将某一指标在不同时间上的不同数值,按照时间先后顺序排列而成的数列。 类似关联规则挖掘
-
定义
从大量的时间序列数据中提取人们事先不知道的、但又是潜在有用的与时间属性相关的信息和知识。
-
作用
- 用于短期、中期或长期预测, 指导人们的社会、经济、军事和生活等行为。
- 通过对过去历史行为的客观记录分析,揭示其内在规律, 进而完成预测未来行为等决策性工作。
- 通过研究信息的时间特性,深入洞悉事物进化的机制,是获得知识的有效途径。
7 Web挖掘的主要数据源
- Web服务器日志数据
- Web上的电子商务数据
- Web上的网页
- Web上的网页之间的链接
- Web上的多媒体数据
8 权威页面和中心页面
-
HITS(Hyperlink-Induced Topic Search)是遵照寻找权威 页面和中心页面的典型方法,基于一组给定的关键字,可 以找到相关的页面。
-
权威页面
是指包含需求信息的最佳资源页面。是指与某个领域或者某个话题相关的高质量网页
中心页面
是一个包含权威页面链接的页面。
9 EM算法
-
定义
最大期望算法(Expectation-maximization algorithm,EM)在概率模型中寻找参数最大似然预计或者最大后验预计的算法。用于寻找,依赖于不可观察的隐性变量的概率模型中,参数的最大似然预计。
-
步骤
最大期望算法经过两个步骤交替进行计算:
- 计算期望(E),利用对隐藏变量(未知参数)的现有预计值,计算其最大似然预计值;
- 最大化(M)。最大化在 E 步上求得的最大似然值来计算参数的值。M 步上找到的参数预计值被用于下一 个 E 步计算中。
综合题
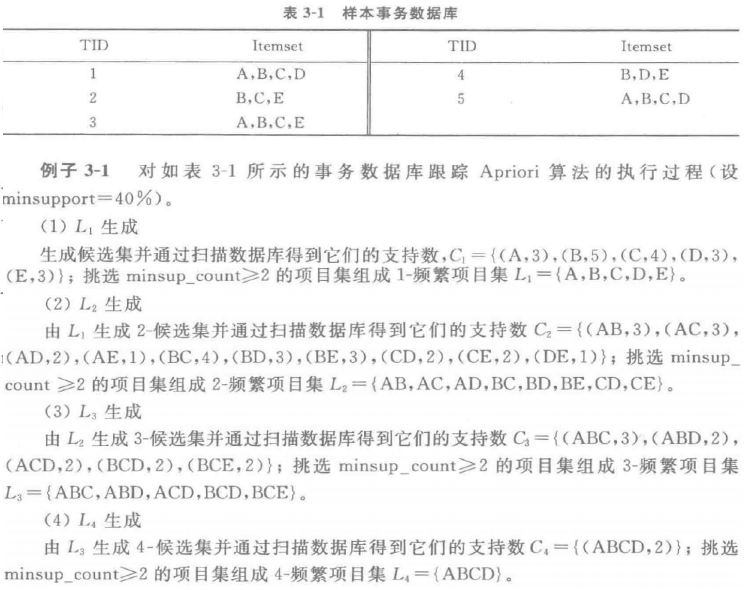
1 Apriori伪代码
-
定义
是一种挖掘关联规则的频繁项集算法 ,其核心思想是通过候选集生成和情节的向下封闭检测两个阶段来挖掘频繁项集。
-
主要步骤
- 扫描全部数据,产生候选1-项集的集合C1.
- 根据最小支持度,由候选1-项集的集合C1产生 频繁1-项集的集合L1.
- 对k>1,重复执行步骤4,5,6
- 由Lk执行连接和剪枝操作,产生候选k+1-项集 的集合 $C_{k+1}$
- 根据最小支持度,由候选(k+1)-项集的集合 Ck+1,产生频繁(k+1)-项集的集合 $L_{k+1}$
- 若L不等于∅,则k=k+1,步骤跳4,否则结束
- 根据最小置信度,由频繁项集产生强关联规则
-
伪代码
算法3-1 Apriori(发现频繁项目集)
输入:数据集D;最小支持数minsup_count
输出:频繁项目集L
算法apriori中调用了apriori-gen $(L_{k-1})$ ,是为了通过(k-1)-频集产生K-侯选集。
算法3-2 apriori-gen $(L_{k-1})$ 候选集产生
输入:(k-1)-频繁项目集 $(L{k-1})$
输出:k-候选项目集 $C{k}$
-
例题
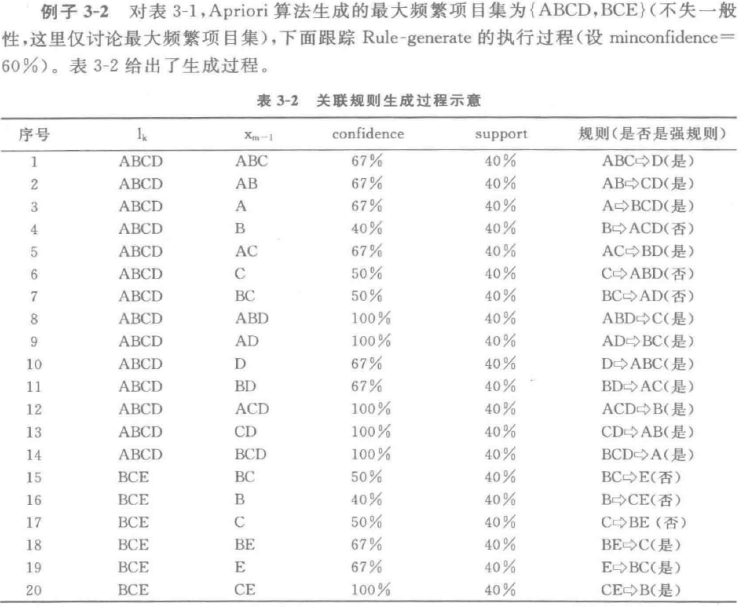
2close算法闭合项集计算
-
原理
- 频繁闭合项目集的非空闭合子集都是频繁闭合项目集。
- 非频繁闭合项目集的闭合超集都是非频繁闭合项目集。
闭合项目集
一个项目集C,当且仅当对于在C中的任何元素,不可能在C中存在小于或等于它的支持度的子集。
算法步骤
(自己写的,加强理解)
- 计算 $FCC_{i}$ 的产生式:数据库中每个个数为 i 的项目集(不重复)
- 计算 $FCC_{i}$ 闭合项目集(closure)并求出支持度(support):找出数据库中所有包含A的项⽬(数据库中的一行)的交集及其支持度(在数据库中包含这个闭合项目集的有几行)
- 修剪候选闭合项目集,得到 $FC_{i}$ :删除小于Min Support的候选闭合项目集(那一行都删除)
- 利用 $FCC{i}$ 的generator生成 $FCC{i+1}$ :将产生式(Generator)两两组合,如果得到的这个新的产生式是① $FCC_{i}$ 的字母的闭合项目集的子集;②其闭合项目集为空(在数据库中不存在这种组合);③非频繁项目集的超集,则删除。
- 重复1.~4.,直至某一步生成的 $FCC_{i+1}$ 为空
- 将闭合项目集的元素个数为i的放到 $L_{i}$ 集合中
- 从 $L{i}$ 最大的集合开始,分解该集合,找到它的所有的(i—1)项子集,如果它不属于 $L{i-1}$ ,则把其加入 $L_{i-1}$
- 重复7.直至 i =2
例题

闭合项集(Closed Itemset)及其支持度
计算闭合项集及支持度:(高概率考)${A}$的闭合项集是指所有包含${A}$的项目的交集,支持度是指${A}$出现的频数


3 KNN伪代码
-
定义
K-近邻分类算法(K Nearest Neighbors,简称KNN)通过计算每个训练数据到待分类元组的距离,取和待分类元组距离最近的K个训练数据,K个数据中哪个类别的训练数据占多数,则待分类元组就属于哪个类别。
伪代码
算法 4-2 K-近邻分类算法
输入: 训练数据T;近邻数目K;待分类的元组t。
输出: 输出类别c。
例题



4 ID3伪代码 信息增益 计算题
-
信息熵
在信息论中,熵是一种信息度量单位。在决策树构造算法中根据熵值来计算信息增益。是对随机变量不确定度的度量,熵越大,随机变量的不确定性就越大。如果一个事件发生的概率是$p(x)$,则其信息熵为$H=log\frac{1}{p(x)}$
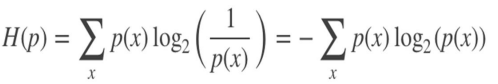
信息增益 计算题
定义(information gain)
针对特征而言的,就是看一特征,系统有它和没有它时的信息量各是多少,两者的差值就是这个特征给系统带来的信息量,即信息增益。
公式
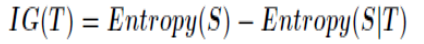
伪代码
-
输入:训练数据集D,特征集A ,阈值 $\epsilon$
-
输出:以node为根节点的——棵决策树

例题 4-5
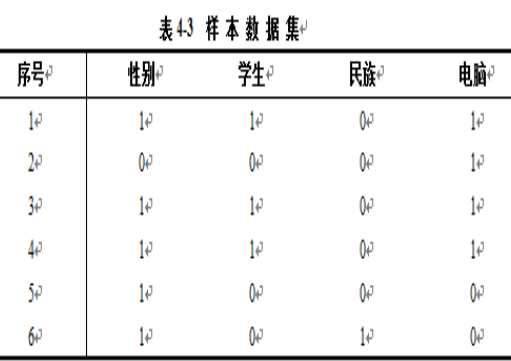
-
给定样本电脑分类所需的期望信息
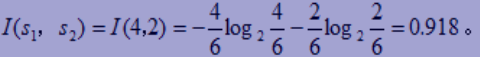
-
计算每个属性的熵
-
性别属性
-
“性别”=1,有3个 “电脑”=1,2个“电脑”=0; $-(\dfrac{3}{5}log{2}\dfrac{3}{5}+\dfrac{2}{2}log{2}\dfrac{2}{5})=0.971$
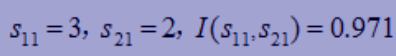
- “性别 ”=0,有1个“电脑”=1,没有“电脑 ”=0。 $-(log_{2}1)=0$
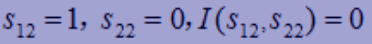
- 信息增益
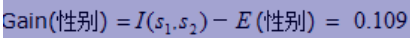
-
类似的,可以计算: Gain(学生)=0.459; Gain(民族)=0.316
-
“学生属性”在所有属性中具有最高的信息增益,首先被选为测试属性
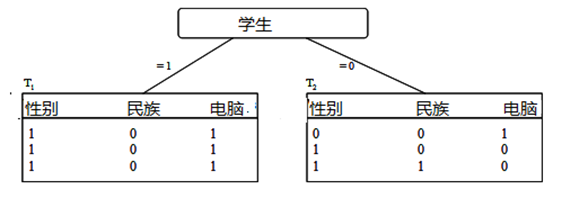
-
左子树的生成过程。对于“学生”=1的所有元组,其类别标记均为1。得到一个叶子结点。
-
右子树需要计算其他2个属性的信息增益:
-
Gain(性别)=0.918;
-
Gain(民族)=0.318;
对于右子树T2,选取最大熵的“性别”
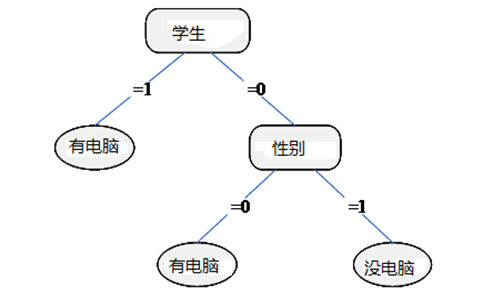
-
-
5 k-means算法描述、伪代码、优缺点
-
考点
会考到用哪种距离函数(看题目要求!)
算法描述

伪代码(AB卷有一个考了)
算法5-1 k-means算法
输入:簇的数目k和包含n个对象的数据库。
输出:k个簇,使平方误差准则最小。
优缺点

例题
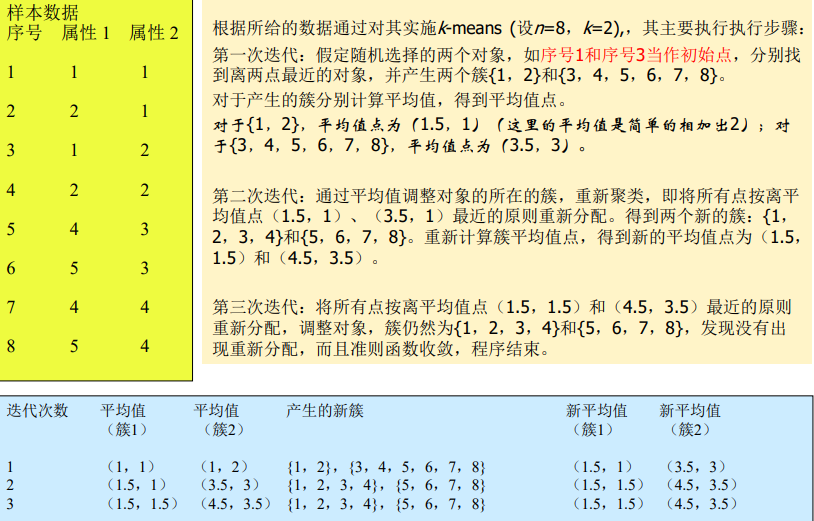
6 AGNES伪代码
-
定义名词解释
AGNES (AGglomerative NESting):自底向上凝聚的算法,先将每个对象作为一个簇,然后这些簇根据某些准则(类间距离最近的两个点)被一步步地合并,直到某个终结条件被满足(达到定义的簇的数目)。(写这些就够了)
两个簇间的相似度由这两个不同簇中距离最近的数据点对的相似度来确定。
伪代码
算法5-3 AGNES(自底向上凝聚算法)
输入:包含n个对象的数据库,终止条件簇的数目k。
输出:k个簇,达到终止条件规定簇数目。- 将每个对象当成一个初始簇;
- REPEAT
- 根据两个簇中最近的数据点找到最近的两个簇;
- 合并两个簇,生成新的簇的集合;
- UNTIL 达到定义的簇的数目;
例题
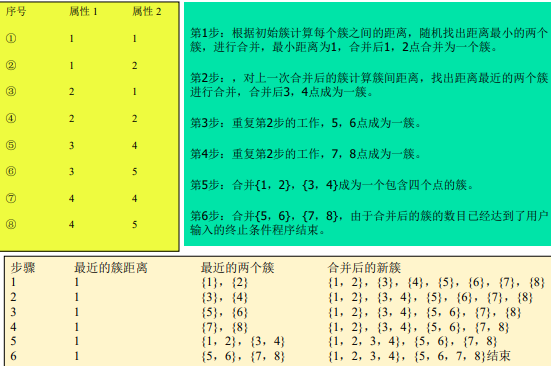
7 DIANA伪代码
-
定义名词解释
DIANA (Divisive ANAlysis):自顶向下分裂的算法,它首先将所有对象置于一个簇中,然后逐渐细分为越来越小的簇,直到达到了某个终结条件(达到了某个希望的簇数目,或两个最近簇之间的距离超过了某个阈值)。

伪代码大题
算法5-4 DIANA(自顶向下分裂算法)
输入:包含n个对象的数据库,终止条件簇的数目k。
输出:k个簇,达到终止条件规定簇数目。
例题 5-4
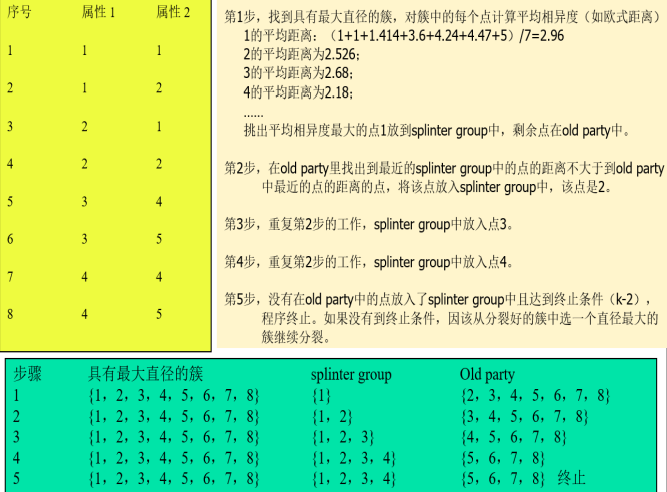
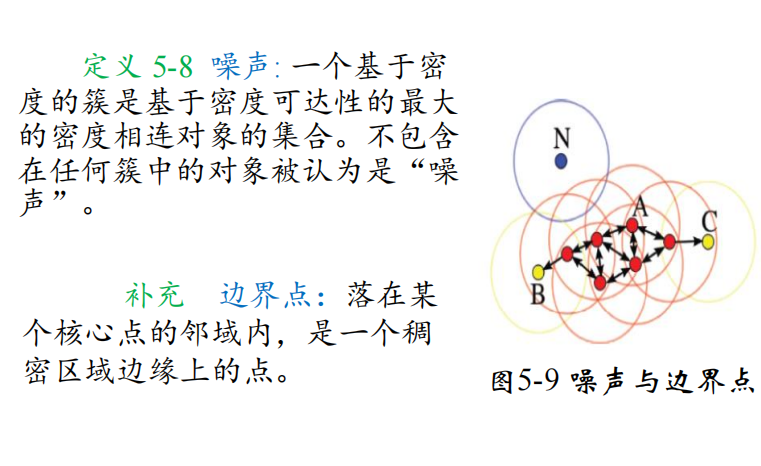
8 DBSCAN算法描述、优缺点
-
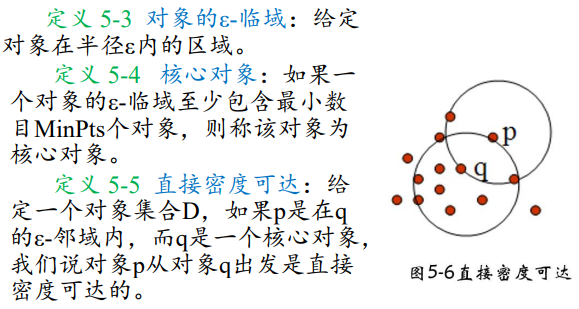
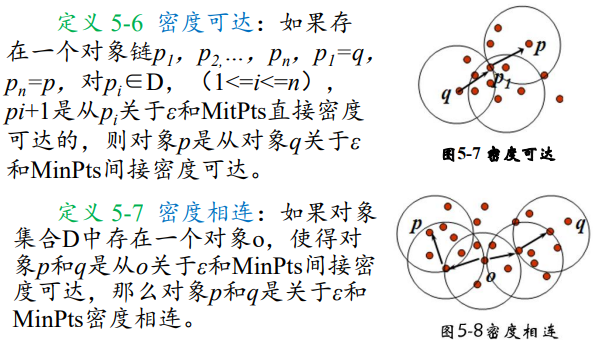
噪声点
不包含在任何簇中的对象被认为是“噪声”。
边界点
落在某个核心点的邻域内,是一个稠密区域边缘上的点。(如果一个簇以边界点为中心,则它以 $\epsilon$ 邻域内不一定包含Min Pts个对象)
定义
DBSCAN(Density-Based Spatial Clustering of Applications with Noise):噪声环境下的密度聚类算法,将密度相连的点的最大集合聚成簇,并可在有“噪声”的空间数据库中发现任意形状的聚类。
特点
事先不知道会有多少个簇
算法描述
如果一个点q的区域内包含多于Min Pts 个对象,则创建一个q作为核心对象的簇。然后,反复地从这些核心对象中寻找直接密度可达的对象,把一些密度可达簇进行合并。当没有新的点可以被添加到任何簇时,该过程结束。
核心思想:将密度相连的核心对象点都放在一个簇中。
相关概念
伪代码(算法描述)10分
算法 5-5
输入:包含n个对象的数据库,半径 ε,最少数目Min Pts。
输出:所有生成的簇,达到密度要求。- DBSCAN通过检查数据集中每点的 $\epsilon$ 邻域来搜索簇, 如果点p的 $\epsilon$ 邻域包含的点多于MinPts个,则创建一个以p 为核心对象的簇;
- 然后,DBSCAN迭代地聚集从这些核心对象直接 密度可达的对象,这个过程可能涉及一些密度可达簇的合并;
- 当没有新的点添加到任何簇时,该过程结束。
优缺点简答题
优点
- 聚类速度快且能够有效处理噪声点和发现任意形状的空间聚类;
- 与K-MEANS比较起来,不需要输入要划分的聚类个数;
- 聚类簇的形状没有偏倚;
- 对噪声数据不敏感。
缺点
- 当数据量增大时,要求较大的内存支持I/O消耗也很大;
- 当空间聚类的密度不均匀、聚类间距差相差很大时,聚类质量较差,因为这种情 况下参数MinPts和 $\epsilon$ 选取困难(对半径和Minpoints敏感)。
- 算法聚类效果依赖与距离公式选取, 实际应用中常用欧式距离,对于高维数据,存在“维数灾难”。
例题
9 PageRank伪代码
-
页面等级(评级)的评价方法

PageRank的核⼼思想
- 如果⼀个⽹⻚被很多其他⽹⻚链接到的话说话这个⽹⻚⽐较重要,也就是PageRank值会相对较⾼
- 如果⼀个PageRank值很⾼的⽹⻚链接到⼀个其他的⽹⻚,那么被链接到的⽹⻚的PageRank值会相应地因此⽽提⾼。
简单pagerank模型(不考)
例题
初始V0代表上网者一开始在哪个页面
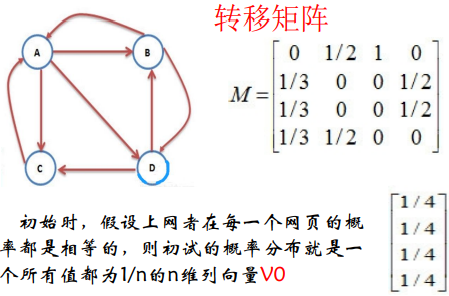

每用Vi右乘一次转移矩阵M,得到第i次点击链接后到达某一页面的概率
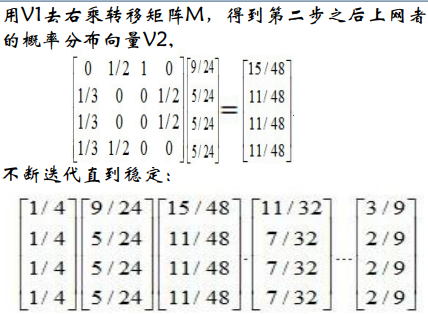
直到Vi稳定,代表不论用户从哪个页面开始访问,经过无数次点击超链接最终到达某个页面的概率,可以计算出某个页面排除了用户点击多少次超链接到达因素后的权重,比较客观。(个人理解)
步骤
- 计算每个网页一个PageRank(PR)值
- 通过(投票)算法不断迭代,直至达到平稳分布为止。
- 根据这个值的大小对网页的重要性进行排序。
基于随机冲浪的PageRank算法(考)
PPT例题
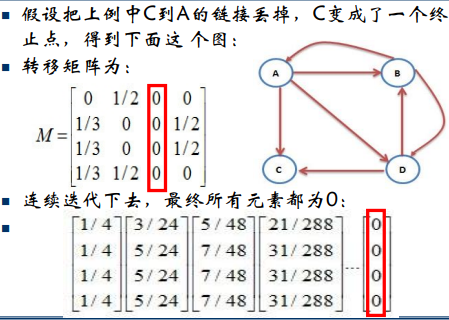
如果某个网页没有指向其它网页的超链接
改进,加入一个系数,代表上网者多大概率 $\alpha$ 点击页面中的超链接,多大概率 $1-\alpha$ 在地址栏键入某个网页的链接。

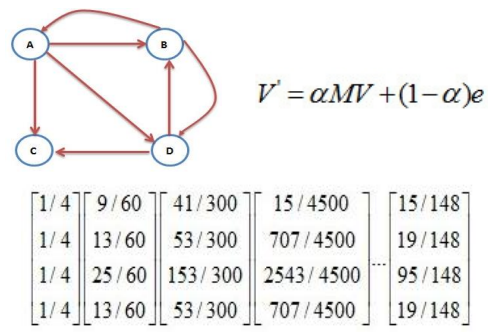
书上例题 7-1

伪代码
算法7-3 基于随机冲浪的PageRank算法
输入:页面链接网络G
输出:页面等级值向量R
其他
1 各类距离
-
距离条件

明可夫斯基距离

两种特殊情况:
欧氏距离

曼哈顿距离

切比雪夫距离
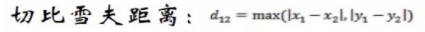
余弦相似度
余弦距离(二维)
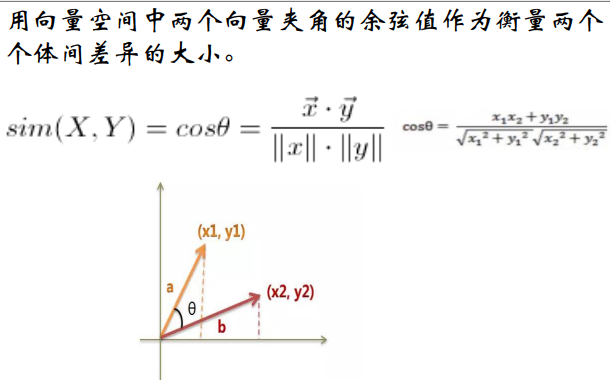
余弦相似度(多维)

Jaccard距离
处理集合,计算离散值距离(前面的距离函数都是计算连续值)
Comments NOTHING